The Mythical Man-Months - thoughts
Posted on 19 March 2024 in Books • 22 min read

As the year 2023 was coming to an end, I finally had some time to recap "The Mythical Man-Month: Essays on Software Engineering" by Fred Brooks. The book talks about software development fallacies from software engineering and project management perspectives. However this is not "yet another book". It was first published in 1975, nearly fifty years ago! So much changed since 1975, and yet, so little! It's unbelievable that today we are still struggling with the problems that haunted us in the age of mainframes.
You smile a lot as you read the book. Programming with punch cards? A big fat machine with only 2 MB of RAM? Software documented on paper? Sure, things were different back then. But there are so many similarities! Instead of reviewing the book, I'd prefer to study these similarities, draw parallels, and find out whether things have changed for the better.
1 - The Tar Pit
Programming is joyful. Every time our program behaves as we intended, it's like a small masterpiece coming to life. However, programming is also full of woes. How many programs - big and small, beautiful and ugly, useful and useless - have been sucked into a tar pit? Initially, it may not be apparent; after all, a creature can pull out one of its paws. But what if it's all four paws are stuck? Therefore, we should learn to avoid such tar pits.
How painfully true! Even in my relatively short career (14 years and counting), I've witnessed software systems - both small and large - struggling under the weight of their features, unable to escape the tar pit and eventually fading away. That's precisely why we begin with Proof of Concepts (PoCs) and Minimal Viable Products (MVPs) and develop systems iteratively. This is why we continuously evolve software architecture - to ensure it remains resilient and elastic - and prevents getting into the tar pit.
2 - The Mythical Man-Months
The second chapter explains why measuring a job in "man-months" is inappropriate for software development.
Men and months are interchangeable commodities only when a task can be partitioned among many workers with no communication among them. This is true of reaping wheat or picking cotton; it is not even approximately true of systems programming.
And yet, we continue measuring software development in "story points" - a measure of task complexity. We even play "agile poker" to determine a reasonable amount of story points. Our teams digest fewer story points when someone is on vacation or sick leave, and more story points when everyone is present. When story points seem too abstract, we convert them into days and hours using arbitrary logarithmic scale. For instance, 1 story point represents couple of hours of development, while 8 story points correspond to about a week of work for a seasoned developer... But wait a second, aren't we back to man-months again?!
Are you playing agile poker? Consider using these accurate estimation cards for the next round:

3 - The Surgical Team
In the third chapter Brooks discusses team efficiency based on size and structure.
For efficiency and conceptual integrity, one prefers a few good minds doing design and construction. Yet for large systems one wants a way to bring considerable manpower to bear, so that the product can make a timely appearance.
How wild does a 200-man team sound? Brooks talks of ever bigger teams - 1000 people working on OS/360. And it's not just programmers but writers, machine operators, clerks, managers and more. Even a brilliant, but small team is not able to tackle work that requires the collective effort of hundreds of minds.
Brooks refers to a proposal by Harlan Mills, where the chunks of work are split between surgical teams. A surgical team includes people in different roles, much like a real surgical team that performs medical operations. There roles include: the surgeon, the copilot, the tester and the toolsmith, the language expert and the editor (i.e. a technical copywriter), the administrator and the secretaries.
Interestingly, you can easily map all these roles to the roles in modern software development teams: Product Owner (PO), team lead, engineer, tester. While some of the roles have been automated and become unnecessary in our age, the essence of the idea - that collaboration and specialization are crucial - remains relevant:
10-man team can be effective no matter how it is organized, if the whole job is within its purview.
4 - Aristocracy, Democracy and System Design
The chapter begins with a photo of the Reims Cathedral, which unlike some of European cathedrals, exhibits sound design and architectural integrity.
The guidebook tells, this integrity was achieved by the self-abnegation of eight generations of builders, each of whom sacrificed some of his ideas so that the whole might be of pure design.
Conceptual integrity is equally important for software systems as for buildings. Think of Unix with its small programs that each excel at a specific task. Can you imagine a "jack of all trades and the master of none" among them? Probably not, because it wouldn't align with the Unix philosophy and wouldn't be accepted by the Unix community. Or imagine a bunch of connected microservices, each written in a different language, deployed across various clouds, collaborating via non-compatible protocols. Such an architecture is a maintenance hell destined to fail.
Conceptual integrity implies that design comes from a limited set of minds.
Brooks argues that to achieve conceptual integrity, the design of the architecture (i.e. the interfaces of the system) must be separated from its implementation. This doesn't mean that the architects are "aristocracy" who make all the decisions. Rather, the architects decide "what should be done", while implementers decide the "how".
5 - The second-system effect
The second is the most dangerous system a man ever designs. When he does his third and later ones, his prior experiences will confirm each other as to the general characteristics of such systems, and their differences will identify those parts of his experience that are particular and not generalizable.
The general tendency is to over-design the second system, using all the ideas and frills that were cautiously sidetracked on the first one.
I believe that overengineering can happen at any stage of one's journey. The fundamental concepts of our field are stable, compared to all the hyped frameworks, tools, programming languages and processes, that claim to solve the issues of their predecessors.
In my experience, the most skilled engineers create the solutions that are simple, elegant and efficient.
6 - Passing the word
How can a group of 10 architects maintain the conceptual integrity of a system which 1000 men are building? This chapter is a perfect example of eternal problems on one hand and technical progress transforming (but not completely eradicating!) the others.
How did people tackle this problem on the verge of 60s and 70s? They used
Written specifications - the manuals.
Formal definitions - API specifications.
I think we will see future specifications to consist of both a formal definition and a prose definition.
Direct incorporation - #include of function definitions in C, or import in Java to ensure correct function signature usage in compile-time.
Conferences and courts - the communities of practice.
Multiple implementations - The definition will be clearer, if there are at least two implementations in the beginning (web standards, compilers etc.)
In most computer project there comes a day when it is discovered that the machine and the manual don't agree. When the confrontation follows, the manual usually loses, for it can be changed far more quickly and cheaply than the machine.
Telephone log - Brooks advises architects to keep recordings of every question and answer, combine and distribute those on a weekly basis - in paper format! We have better tools (no, Confluence is not a better tool!) for this nowadays, and a well structured and up-to-date Q&A log is quite handy!
Product test - we tend to shift left in testing strategies. Software built with good test-first practices and automated integration testing has a solid foundation, yet manual exploratory testing can reveal so much! Independent testing is also necessary to have get the feedback and perspective of the people who were not involved in the development.
The project manager's best friend is his daily adversary, the independent product-testing organization.
Every development organization needs such an independent technical auditing group to keep it honest. In the last analysis the customer is the independent auditor. In the merciless light of real use, every flaw will show. The product-testing group then is the surrogate customer, specialized for finding flaws.
7 - Why did the tower of Babel fail?
This chapter discusses communication, or rather synchronisation problems. Brooks emphasizes the need of an up-to-date workbook - a structure imposed on the documents that the project will be producing.
All the documents of the project need to be part of this structure. This includes objectives, external specifications, interface specifications, technical standards, internal specifications, and administrative memoranda.
Sounds like our issue trackers, rich version control systems (think Github, Gitlab etc.), project wikis (Lord help to keep them in harmony!)
How hard was it? Brooks talks of keeping a workbook on paper - which became 5 feet (~ 1.5m!) thick and daily change distributions consisting of 150 pages! Microfische was a huge step forward which according to Brooks saved millions of dollars on wasting paper.
With today's system technology available, I think the technique of choice is to keep the workbook on the direct-access file, marked with change bars and revision dates. Each user would consult it from a display terminal. A change summary, prepared daily, would be stored in LIFO fashion at a fixed access point. The programmer would probably read that daily, but if he missed a day he would need only read longer the next day.
On a smaller scale - a good CHANGELOG is a crucial part of any system's API.
8 - Calling the shot
How long will a system programming job take? How much effort will be required? How does one estimate? Half a century later, we are still bad at answering these questions.
In the past, a common measure of system complexity was the number of instructions it contained. The chapter is mostly dedicated to that topic, which is quite outdated by today's standards. However, we can still draw parallels, for example,the effort required to create and maintain a system grows exponentially with its size:
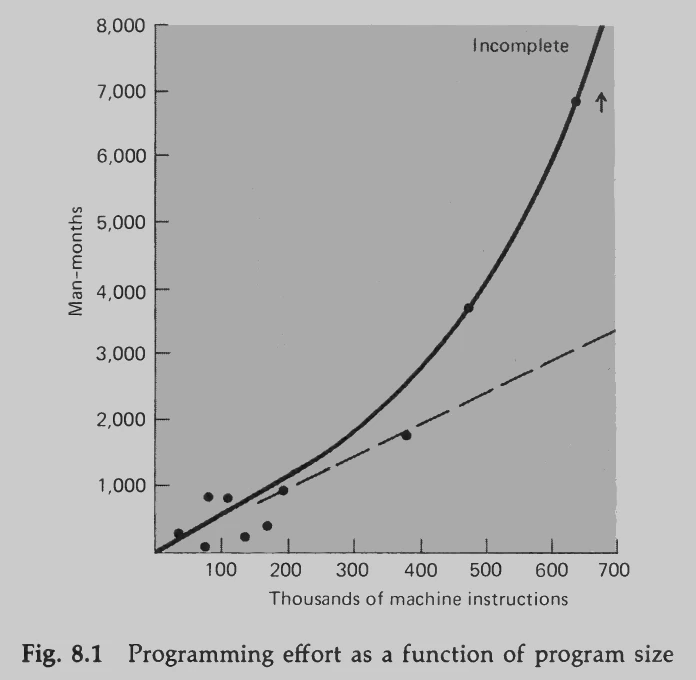
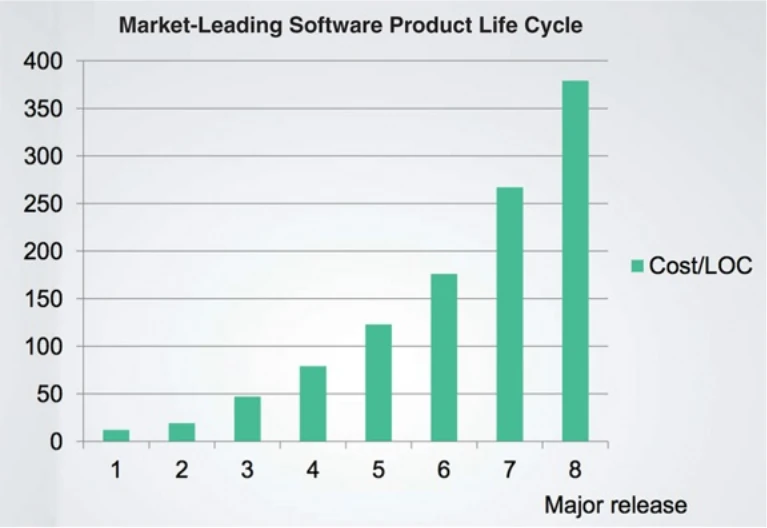
compare to the "Cost per line of code" chart from "Clean Architecture":
9 - Ten Pounds in a Five-Pound sack
Talks of the costs we tend to often forget.
Consider the IBM APL interactive software system. It rents for $400 per month and, when used, takes at least 160K bytes of memory. On a Model 165, memory rents for about $12 per kilobyte per month. If the program is available full-time, one pays $400 software rent and $1920 memory rent for using the program.
Projecting this to the present day, a t3.2xlarge EC2 AWS instance with 32GiB of memory costs $0.333 per hour. This is roughly $0.00000714 per KiB per month - almost 1.7 Million times cheaper than Model 165 memory usage costs. This insane leap took half a century, and we are not slowing down. However, our systems have evolved as well. They grew in complexity, now serving millions of customers concurrently, streaming high-quality video, and processing real-time AI tasks. Consequently, despite more affordable hardware and broader network bandwidth, we still have to pay the price.
It’s a timeless truth: we've got to keep an eye on our budgets and watch how we're using our resources. Whether it’s CPU, memory, network bandwidth, storage, file sizes, startup time - you name it - we need to track it all.
Finally the following advice caught me off-guard, but then I recalled the world of embedded programming, where it makes total sense:
Every project needs a notebook full of good subroutines or macros for queuing, searching, hashing, and sorting. For each such function the notebook should have at least two programs, the quick and the squeezed.
10 - The Documentary Hypothesis
The documentary hypothesis states that
Amid a wash of paper, a small number of documents become the critical pivots around which every project 's management revolves. These are the manager's chief personal tools.
Brooks presents examples of documents from various projects and discusses the necessity of formal documentation. He states that the least questions these documents should address are: what, when, how much, where, and who. Take a software project, for instance:
- What: objectives and product specifications
- When: schedule
- Where: space allocation
- How much: budget
- Who: organization chart - more on this one just in few paragraphs
Why have formal documents? Brooks emphasizes three matters:
- Writing the decisions down is essential. It's only when we write things down, that the gaps and inconsistencies become evident.
- The documents communicate the decisions to others.
- Manager's documents provide them with a database and a checklist. Periodic reviews allow managers to assess their current status and determine necessary changes in focus or direction.
Brooks mentions Conway's law when talking of organization structure that will work on the software project.
Conway goes on to point out that the organization chart will initially reflect the first system design, which is almost surely not the right one. If the system design is to be free to change, the organization must be prepared to change.
Indeed, Team Topologies teaches us that we need to arrange teams according to the desired architecture and design, not vice versa. As the design and architecture evolve, so should the team topologies involved in product development.
To some extent, everything discussed in this chapter remains relevant to project management today.
11 - Plan To Throw One Away
So often we conflate the purpose and meaning of “Proof of Concept” with that of a “Minimal Viable Product”. A team working on a PoC might be forced to carry on with it to production, rather than starting from scratch and properly building the system from the ground up, applying the insights acquired during the PoC phase. There is nothing new under the Sun:
The management question, therefore, is not whether to build system and throw it away. You will do that. The only question is whether to plan in advance to build a throwaway, or to promise to deliver the throwaway to customers. Seen this way, the answer is much clearer. Delivering that throwaway to customers buys time, but it does so only at the cost of agony for the user, distraction for the builders while they do the redesign, and a bad reputation for the product that the best redesign will find hard to live down.
There is so much wisdom in these words. A PoC is a tool to test a business hypothesis and should be considered a throwaway. Delivering the PoC as a finished solution to the customer always backfires: developing on a weak foundation eventually leads to a collapse.
The next topic is - The Only Constancy Is Change Itself.
Both the actual need and the user’s perception of that need will evolve as programs are developed, tested, and utilized. The "throw-one-away" concept is essentially an acknowledgment that learning leads to changes in design. That’s precisely why we must plan the system for change.
The ways of designing a system for each change are well known and widely discussed in the literature perhaps more widely discussed than practiced.
Isn't it painful? We understand the need to design and implement and the system, keeping the need for change in mind. Yet so many systems eventually collapse under their own weight! Making changes to these systems becomes more expensive than not touching the systems at all.
Should we plan for change only in software systems? Brooks answers this by referencing J. Cosgrove's paper "Needed: a new planning framework", where Cosgrove advocates for treating all plans, milestones, and schedules as provisional to facilitate change. Although the section is only four pages long, it contains ideas that have been extensively discussed in "Accelerate", "The DevOps Handbook", "Team Topologies" and other studies. These include continuous learning and experimentation across various domains, team-first thinking, effective communication, facilitating (surgical) teams, the importance of leadership, and more.
Finally, Brooks discusses system maintenance, which he defines as the period following a program’s installation for a customer:
The total cost of maintaining a widely used program is typically 40 percent or more of the cost of developing it. Surprisingly, this cost is strongly affected by the number of users. More users find more bugs.
Software-as-a-Service has transformed the landscape such that software may never enter a traditional maintenance phase in its entire lifetime. However, without a solid architecture and a team committed to continuous improvement, an increasing amount of time will be devoted to bug fixing, to the point where a “complete rewrite” becomes a more viable option.
Theoretically, after each fix one must run the entire bank of test cases previously run against the system, to ensure that it has not been damaged in an obscure way. In practice such regression testing must indeed approximate this theoretical ideal, and it is very costly.
Today, regression testing is cheap. We have fantastic tools to fulfill the test pyramid. Test-first development of software has become the standard. Each modern programming language and environment comes with a handful of unit testing frameworks and libraries. Tools like Docker and Testcontainers enable us to set up a real database with a actual message brokers for integration testing. Even end-to-end (E2E) tests can be automated.
12 - Sharp tools
From laptops, IDEs, CI services, and Source Code Management systems to phones, circuit boards for debugging, and even the comfort of office chairs - we rely heavily on our tools. Nowadays, tools are generally much more affordable compared to personnel costs. Any savings made by not acquiring the best tools often result in losses due to slower market entry. However, tools weren’t always so affordable, particularly in the early days of computing.
Brooks discusses the machines required by development teams, which needed at least 1 MB of main storage and 100 MB of additional online disk storage, along with terminals. There were other constraints as well. Remember that machine time was a costly commodity? This led to the scheduling of machine access among developers, often limiting them to a few 20-minute sessions during a workday.
Another common challenge was that the target computers for the final product were not the same ones developers used to create the systems. Either the target machines were too expensive, or they weren’t available yet. Brooks also touches on machine simulators, performance simulators, documentation systems, and, finally, high-level programming languages and interactive programming!
In my view, the jewel of this chapter is the discussion on the Segregation of Duties (SoD) in the software release process. If you ever experienced a heavy, multi-gate release processes keep in mind that it was not invented recently!
When a man had his component ready for integration into a larger piece, he passed a copy over to the manager of that larger system, who put this copy into a system integration sublibrary. Now the original programmer could not change it, except by permission of the integration manager. As the system came together, the latter would proceed with all sorts of system tests, identifying bugs and getting fixes. From time to time a system version would be ready for wider use.
Then it would be promoted to the current version sublibrary. This copy was sacrosanct, touched only to fix crippling bugs. It was available for use in integration and testing of all new module versions.
13 - The Whole and The Parts
How does one build a program to work? How does one test a program? And how does one integrate a tested set of component programs into a tested and dependable system? These topics were briefly touched in the book, in this chapter Brooks considers them more systematically.
Brooks begins by emphasizing the significance of Conceptual Integrity in system architecture. He then advocates for testing the Specification before any implementation starts. Consider clients testing a platform API solely based on specification, prior to the platform's implementation being ready. This approach can reveal numerous issues, such as unclear or missing specification pieces, API inconsistencies, lack of documentation etc., all of which may arise during the implementation of client-to-platform communication.
Top-Down design - a method formalized by Niklaus Wirth in 1971 paper - in Brook's opinion, was the most significant new programming formalization of the decade:
Briefly, Wirth's procedure is to identify design as a sequence of refinement steps. One sketches a rough task definition and a rough solution method that achieves the principal result. Then one examines the definition more closely to see how the result differs from what is wanted, and one takes the large steps of the solution and breaks them down into smaller steps.
From this process one identifies modules of solution or of data whose further refinement can proceed independently of other work. The degree of this modularity determines the adaptability and changeability of the program.
Wirth advocates using as high-level a notation as is possible at each step, exposing the concepts and concealing the details until further refinement becomes necessary.
This is a simple and yet a very effective procedure. We can prevent implementation details from impacting architecture, and concentrate on the interaction between its components - starting from the grand scale all the way down to the details. Sounds familiar? That's right, it's Clean Architecture for you.
As I write these lines, another though strikes me: design comes second. It follows the gathering the user stories, the mapping of events, and identification of the needs of all involved stakeholders. Unless we get that right, the system won't address the problems of its end-users, no matter how impeccable the design is.
We've focused a lot on design, but what else does Brooks mention in this chapter?
Structured programming: on the verge of the 60s and 70s, programmers commonly controlled the flow with GOTO statements. Brooks recommends the use of do/while loops and if-then-else statements instead. While we have made significant progress in programming languages development, we still employ these simple program building blocks. Moreover, loops and conditional statements form the basis of syntactic sugar provided by modern programming languages.
The next topics are about debugging, which wasn't straightforward at all:
The programmer carefully designed his debugging procedure planning where to stop, what memory locations to examine, what do find there, and what to do if he didn't. This meticulous programming of himself as a debugging machine might well take half as long as writing the computer program to be debugged.
Just reading about these challenges makes you appreciate the simplicity of setting a breakpoint and using a rich interactive debugger.
At the end of the debugging section, Brooks discusses what we now refer to as test doubles:
One form of scaffolding is the dummy component, which consists only of interfaces and perhaps some faked data or some small test cases. For example, a system may include a sort program which isn't finished yet. Its neighbors can be tested by using a dummy program that merely reads and tests the format of input data, and spews out a set of well-formatted meaningless but ordered data.
As previously mentioned, modern programming provides fantastic tools to design and execute tests and test doubles. Test-first development is not a luxury, but a necessity that ensures code maintainability as it grows.
Brooks concludes by addressing the control of changes, also known as Segregation of Duties (SoD), advocating for the addition of one component at a time and the quantization of updates. This involves releasing in small batches and conducting thorough regression testing.
What tools assist us in these tasks nowadays? Version Control Systems, test-first development with comprehensive unit and integration testing, continuous integration and continuous delivery, and the strategic launch of new features through dark launches and canary releases.
14 - Hatching a catastrophe
This chapter could be perfectly illustrated by the following meme:

Well, developers are not always the guilty party, are they?
When one hears of disastrous schedule slippage in a project, he imagines that a series of major calamities must have befallen it. Usually, however, the disaster is due to termites, not tornadoes; and the schedule has slipped imperceptibly but inexorably.
Yesterday a key man was sick, and a meeting couldn't be held. Today the machines are all down, because lightning struck the building's power transformer. Tomorrow the disk routines won't start testing, because the first disk is a week late from the factory. Snow, jury duty, family problems, emergency meetings with customers, executive audits the list goes on and on. Each one only postpones some activity by a half-day or a day. And the schedule slips, one day at a time.
Brooks asserts that the optimal way to manage a large project is to establish a schedule with defined milestones. Each milestone must be concrete, specific, and measurable.
It is more important that milestones be sharp-edged and unambiguous than that they be easily verifiable by the boss. Rarely will a man lie about milestone progress, if the milestone is so sharp that he can't deceive himself.
This advice is universally applicable, whether in software development or room cleaning. For instance, a ticket stating “Make the server respond faster” is inadequate. What does “faster” mean in this context? Which responses are deemed slow? A more precise ticket would be “Reduce the response time for Resource API endpoints from 500ms to a maximum of 250ms.”
Brooks praises PERT charts for visualizing the dependencies between activities necessary to complete the project and identifying the critical path - the sequence of interdependent activities that take the longest to complete. It also indicates how much an activity can be delayed before it impacts the critical path.
The preparation of a PERT chart is the most valuable part of its use. Laying out the network, identifying the dependencies, and estimating the legs all force a great deal of very specific planning very early in a project. The first chart is always terrible, and one invents and invents in making the second one.
I have no personal experience with PERT charts, so I cannot comment. However, I’m interested in your thoughts on the matter!
Finally, Brooks discusses human behavior in scenarios where a schedule begins to fall behind. Please indulge me not making commenting on this too, Instead, I suggest reading "Tribal Leadership" and "Turn the Ship Around!".
15 - The other face
What is the other face of a program? According to Brooks, it’s the documentation, whether it’s for the user or a technical manual.
Pause for a moment and consider the year 1970. There was no StackOverflow, no Internet, and not even a terminal for every programmer. Without comprehensive documentation accompanying the program, it would be virtually useless.
But even back then, Brooks advocates shipping a program with tests!
Every copy of a program shipped should include some small test cases that can be routinely used to reassure the user that he has a faithful copy, accurately loaded into the machine.
Then one needs more thorough test cases, which are normally run only after a program is modified. These fall into three parts of the input data domain:
- Mainline cases that test the program's chief functions for commonly encountered data.
- Barely legitimate cases that probe the edge of the input data domain, ensuring that largest possible values, smallest possible values, and all kinds of valid exceptions work.
- Barely illegitimate cases that probe the domain boundary from the other side, ensuring that invalid inputs raise proper diagnostic messages.
Nowadays, we seldom need to verify that a faithful copy has been accurately loaded into the machine, but a regression test suite remains absolutely essential - both during development and upon the delivery of a program.
A well-designed test suite also acts as documentation of a program’s capabilities. A specification by example, with automated tests included, precisely documents what a program does.
Brooks recommends including a technical overview of the program to facilitate easy modification. This should encompass a flow chart, descriptions of the algorithms used, explanations of file layouts, and even the pass structure - the sequence in which programs are transferred from tape or disk. Finally
A discussion of modifications contemplated in the original design, the nature and location of hooks and exits, and discursive discussion of the ideas of the original author about what modifications might be desirable and how one might proceed. His observations on hidden pitfalls are also useful.
All this reminds of ARCHITECTURE.md.
The next topic Brooks emphasizes is Self-Documenting Programs. As stated in the book, the adoption of high-level languages was not mainstream at all. Programs were written in machine codes, which is (sarcastically speaking) intended for machines, not for human comprehension. However, even with machine code, it was possible to use human-friendly symbolic names, labels, declaration statements, etc. Comments were just as important. Just have a look at this listing, which carries the unmistakable aroma of the "old school" days:

Brooks uses this listing as an example and explains the techniques used to document it.
Today, we still struggle with writing self-documenting code. “Clean Code,” “Code Complete,” “The Art of Readable Code,” “A Philosophy of Software Design” wouldn't exist if high-level languages had solved all the problems. Engineers still name variables a, b, c. Software is still written without any tests. Specifications still come in the form of poorly-written JIRA tickets, which look nothing like actual specifications. Oh, I’m ranting again. :)
17 - No Silver Bullet
"No Silver Bullet - Essence and Accident in Software Engineering" (1986) is perhaps the most renowned essay by Brooks. It was included in the anniversary edition of the Mythical Man-Months, republished in 1995. The paper's opening statement immediately takes you to the point:
There is no single development, in either technology or management technique, which by itself promises even one order-of-magnitude improvement within a decade in productivity, in reliability, in simplicity.
Brooks differentiates between essential and accidental complexities in the software development process.
Essential complexity comes from the abstract nature of software's building blocks: algorithms, data sets and their relationships. Yet, they must be highly precise and richly detailed. There are countless ways to write a "Hello world" program. What is to be said of anything more complicated?
Brooks suggests attacking essential complexity by reducing productivity constraints. He identifies several promising strategies: Buy versus build, Requirements refinement and rapid prototyping, Incremental development - growing, not building, software, and Employing great designers. All these ideas have stood the test of time and are parts of modern software development.
Accidental complexity comes from limitations of tools, processes, hardware and the environment. For instance, high-level languages alleviate the accidental complexity of assembly language. Iterative software development prevents us from committing to extensive upfront designs, only to discover later that what we've released doesn't meet the customer needs. Having more computing power in our pockets than we had in our desktops just a few decades ago enables the use of more sophisticated algorithms that now run in a reasonable time frame.
Brooks evaluates technical advancements that have been praised as potential silver bullets: Ada and other high-level language advances, Object-oriented programming, Expert systems, Graphical programming, Program verification, Environments and tools, Workstations, finally AI and Automatic programming.
Looking at the latter through the lens of 2024 - Generative Pre-Trained Transformers (GPTs) and Large Language Models (LLMs) are flourishing. We can interact with these tools in natural language and receive code with explanations in return. The interaction doesn't stop there; these tools can maintain context, allowing us to refine queries for more targeted and sophisticated results. Is this sort of automatic programming a silver bullet? In my opinion - no, at least not yet.
Now, don't get me wrong, we can throw a colossal amount of computing power to build a vast, boundless model, capable of holding an entire Linux kernel with all its development history in the context. But the output is still intended for human interpretation. How much can we trust the code generated by such LLMs? How do we verify its correctness? Would we use another LLM to generate tests, or would we craft tests in the traditional way? Let's get back to this discussion in five years - it's going to be interesting!
16 - EPILOGUE
The tar pit of software engineering will continue to be sticky for a long time to come. One can expect the human race to continue attempting systems just within or just beyond our reach; and software systems are perhaps the most intricate and complex of man's handiworks. The management of this complex craft will demand our best use of new languages and systems, our best adaptation of proven engineering management methods, liberal doses of common sense, and a God-given humility to recognize our fallibility and limitations.